What happens if the GPU crashes while answering your ChatGPT request.
Introduction
Large Language Models (LLM) are becoming increasingly popular for numerous tasks, including chatbots, content generation (text, images or videos), translation, etc.
LLM users interact with such systems by sending a prompt, a text describing their request. The LLM then generates the answer by leveraging a set of GPUs in a process called inference, after which they send back the answer to the user.
Compared to previous machine learning systems, state-of-the-art LLMs require hundreds of GB of GPU memory, while high-end GPUs such as the NVIDIA A100 possess only 80GB of RAM. This requires splitting the model on multiple GPUs.
Unfortunately, large-scale GPU deployments are prone to failures, as demonstrated by Eisenman et al. and Patel et al..
When a failure occurs during inference, the user request needs to be recomputed from the beginning, which incurs additional latency and computation. Some researchers are thus making LLM inference fault-tolerant.
In this post we will detail the LLM inference mechanism, present some experiments done on A100 GPUs, and finally describe the DéjàVu system for fault-tolerant LLM inference.
LLM inference in a nutshell
LLM inference is a multi-phases process, as shown in the below figure with a user sending the prompt "Tokyo is".
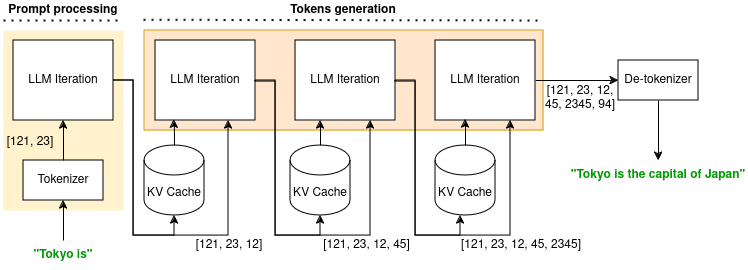
The model first tokenizes it and outputs a set of numerical values, called tokens, understandable only by the model. The tokens are then processed by the LLM for one iteration. These two computations define the prompt processing phase. This phase outputs both a context, saved in a Key-Value cache (KV cache), and a new token.
The second phase of inference is the token generation phase, where all the remaining tokens of the answer are computed. A single LLM iteration computes one new token, with the previous context (stored in the KV cache) and token as inputs. It outputs the new context that will be saved in the KV cache and a new token.
Finally, the LLM translates the tokens to human readable output in a process similar to accessing a lookup table. This output ("Tokyo is the capital of Japan" in the above figure) is sent back to the client.
To tolerate faults, one idea is to persist the KV cache so that the request can be recomputed from its latest state before the failure rather than from the beginning.
Our experiments
We run several experiments on two A100 GPUs (each having 80GB of RAM) with the OPT-13B model. Loading the model allocates 40GB of memory per GPU. Batch size is set to 8. The goal is to evaluate the potential latency gain by implementing a persistent KV cache.
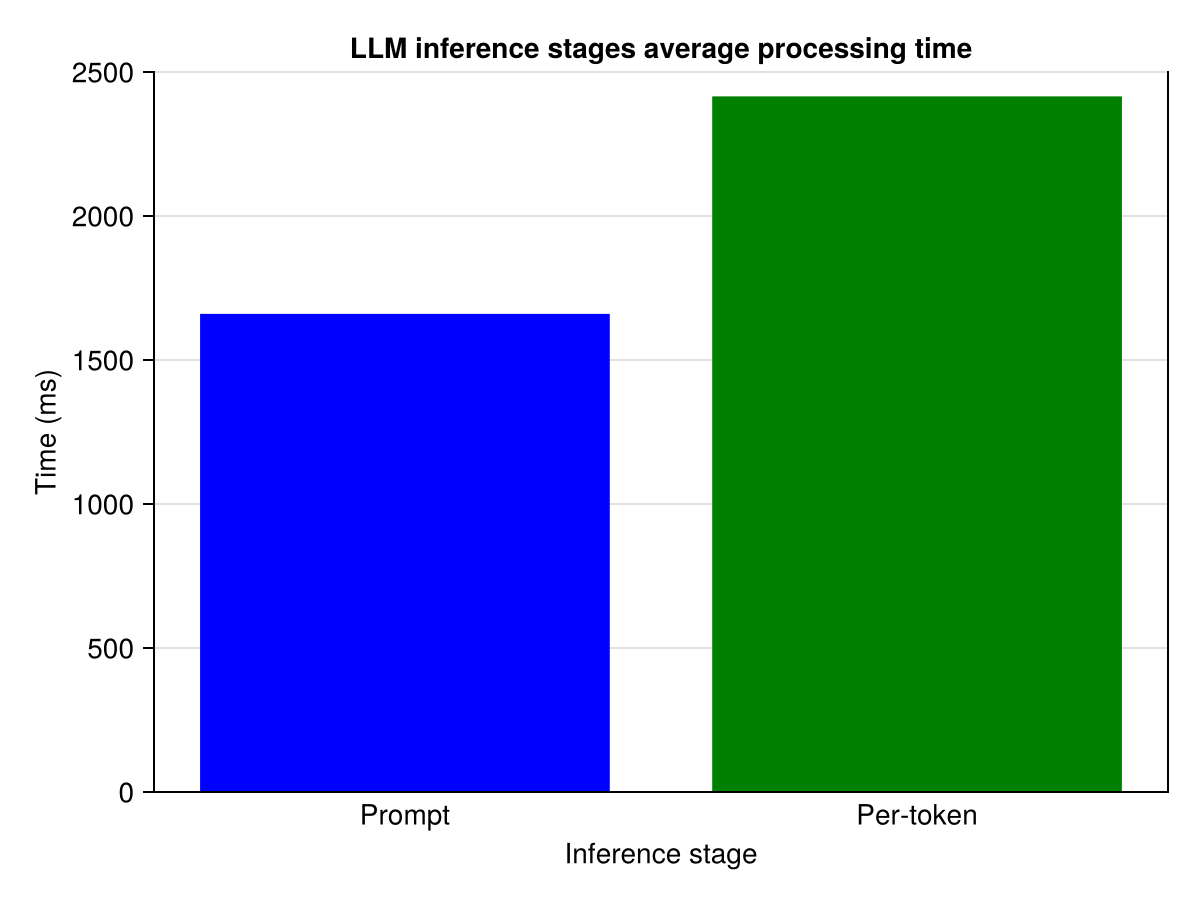
In a first experiment we measure the average processing time of each inference stages average processing time. The experiment stops after having generated a total of 2000 tokens (including the 40 tokens of the prompt). As can be observed in the figure below prompt processing takes 1.7s while a single token generation takes 2.4s. A single failure during inference thus leads to several seconds of delay.
In a second experiment we replay the Microsoft Azure code trace while introducing failures. A given percentage of requests fails, that is to say the GPU has to recompute it from the start.
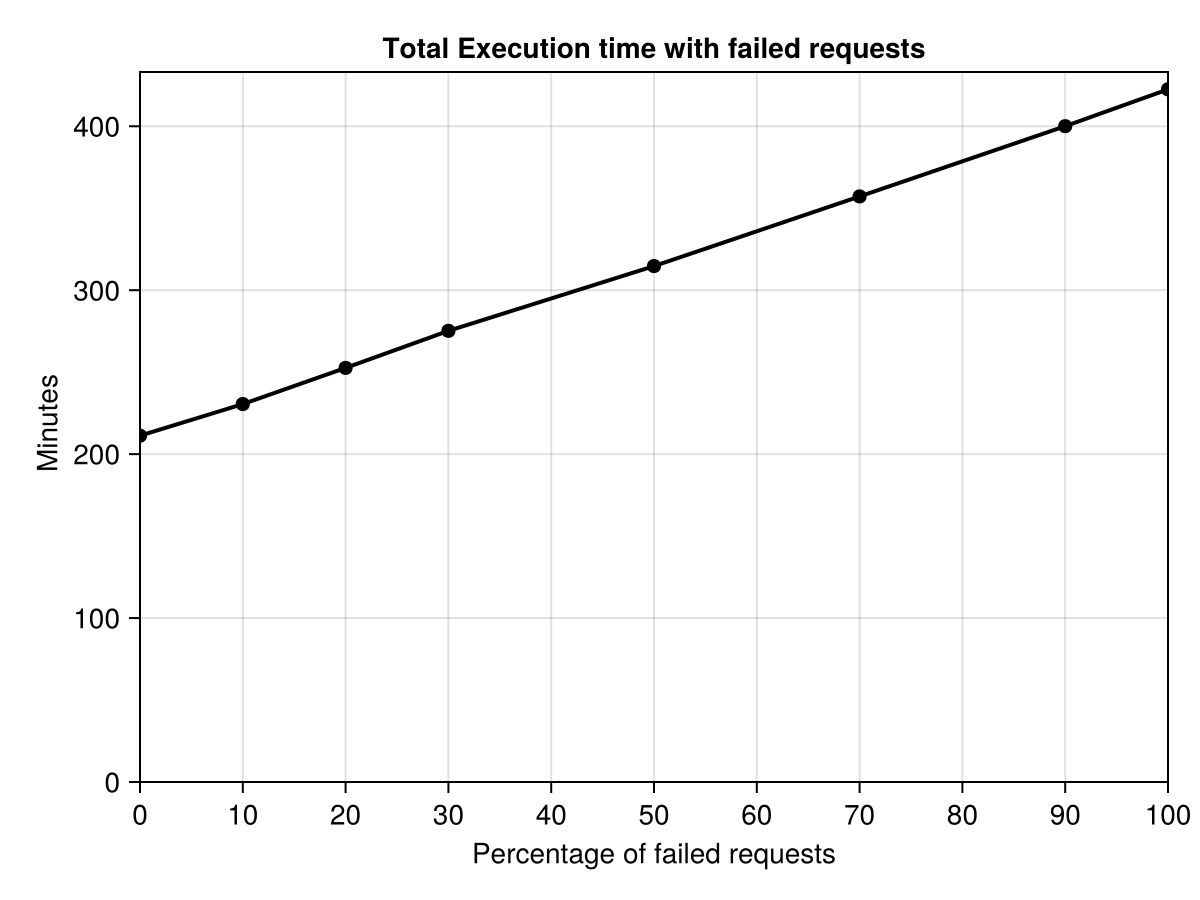
Results are reported in the figure below. Without failures, the entire trace is replayed in 253 minutes (a bit over 4 hours). When introducing failures, this execution time increases: 277 minutes with 10% of failed requests, 303 minutes with 20%, and so on, up to 507 minutes with 100% of failed requests (i.e., all requests need to be executed twice). This represents an increase from 9% (10% failures) to 100% (100% failures).
DéjàVu
DéjàVu is a fault-tolerant system for LLM inference system is a system presented by Strati et al. at the 41st International Conference on Machine Learning (2024). The figure below, taken from the research paper, describes its architecture.
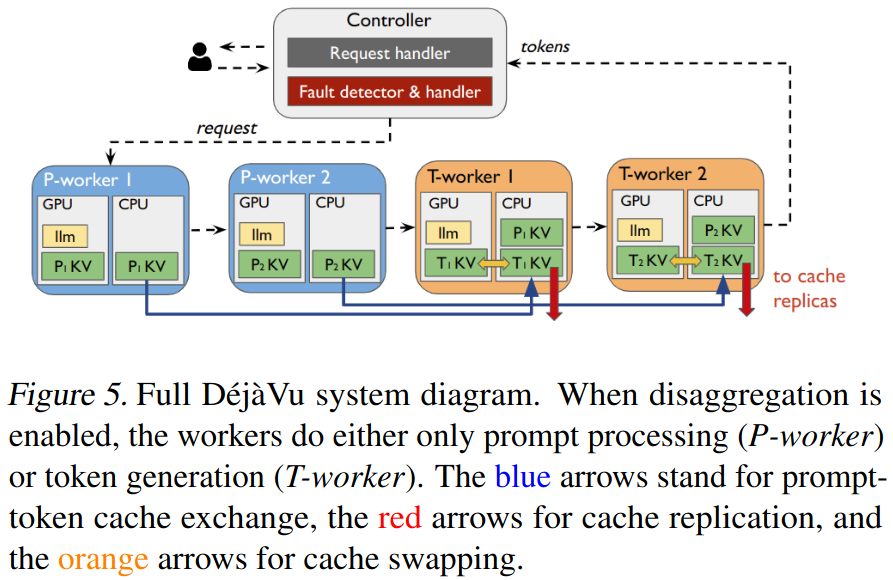
DéjàVu replicates the KV cache in persistent storage or main memory. In case of failures, the KV cache can be restored from the latest available backup instead of having to redo the inference from zero.
To be able to detect a failure, GPUs periodically send heartbeat messages to a central controller component. If he does not receive a heartbeat from a particular GPU after a given period of time, then it assumes the GPU to be faulty.
To efficiently stream (i.e., send) the KV cache to the host CPU, DéjàVu aggregates KV cache updates in a single continuous area of the GPU memory. This makes GPU transfers more efficient, as they can use the full GPU bandwidth, compared to transferring small and non-contiguous GPU memory areas one at a time.
DéjàVu proposes other optimisations, such as executing prompt processing and token generation on different sets of GPUs to avoid conflicts between these two tasks.
DéjàVu has been evaluated on real hardware, with A100 GPUs. The authors show that, in the fault-free case, it outperforms FasterTransformer (the baseline) by 2x while providing low latency (see below).
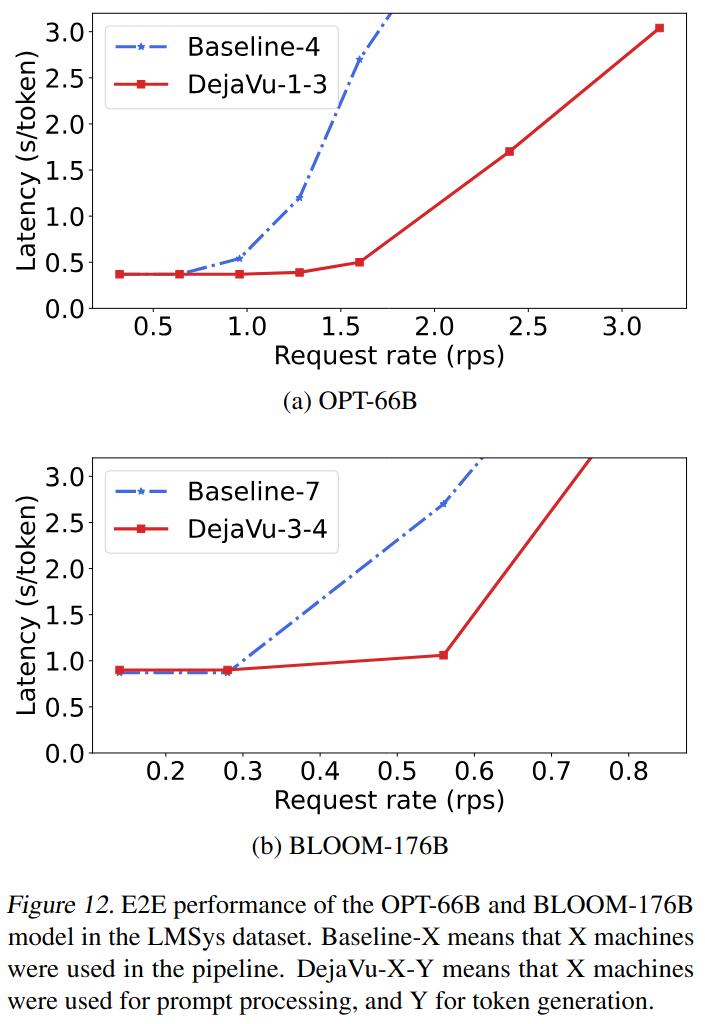
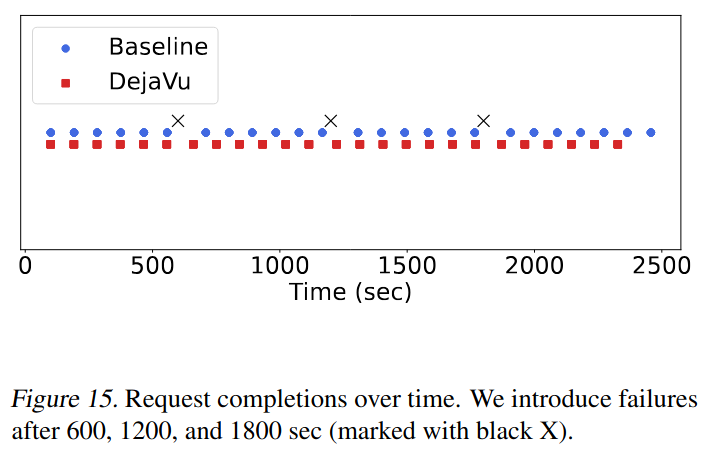
In the faulty case, DéjàVu is able to finish execution 16% faster than the baseline thanks to its fault-tolerant replicated KV cache (see figure below).
Conclusion
In this post we have argued that failures during the LLM inference process is a problem, as requests need to be re-executed from zero, which increases the latency perceived by the client.
We ran several experiments on two A100 GPUs, increasing the percentage of faulty requests (i.e., requests that need to be re-executed). A low percentage of failures such as 10% already means that executing the entire set of requests will take 10% more time.
Finally, we presented DéjàVu, a system that brings fault-tolerance to LLM inference by smartly replicating the KV cache, storing the intermediate state of the LLM inference process. As a result, requests can be restarted from a point close to the GPU failure instead of from zero.
Acknowledgements
We are grateful to IIJ Cloud Division for giving us access to their GPUs.